The post Blockchain Technology for beginners first appeared on TheHackWeekly.com.
]]>Deprecated: Creation of dynamic property OMAPI_Elementor_Widget::$base is deprecated in /home3/thehackw/public_html/wp-content/plugins/optinmonster/OMAPI/Elementor/Widget.php on line 41
Deprecated: Creation of dynamic property Jetpack_Carousel::$localize_strings is deprecated in /home3/thehackw/public_html/wp-content/plugins/jetpack/modules/carousel/jetpack-carousel.php on line 523

Table of Contents
1. Blockchain Terminologies
- HODL
- Transaction
- Gas Fees
- Validation of a block
- NFT
- Defi
- Mnemonic phrase
- Staking
- Wallets
- Web3
- Smart Contracts
- P2P Network
- Blockchain
- Fiat
2. Introduction to Blockchain
3. What are the Popular Consensus Protocols ?
- Proof of Work (PoW)
- Proof of Stake (PoS)
- Delegated Proof of Stake (DPoS)
- Proof of Elapsed Time (PoET)
- Proof of Authority (PoA)
- Proof of Space (PoSpace)
- Proof of History (PoH)
4. What are Whitepapers?
5. Some Popular Blockchain
- Bitcoin
- Ethereum
- Polkadot
- Hyperledger Fabric
- Tezos
- Stellar
- Solana
- Avalanche
6. Safety from Scams
7. Conclusion
1. Blockchain Terminologies
1.0 Crypto
- Crypto or crypto-currency, is a digital currency designed to work as a medium of exchange through a computer network that is not reliant on any central authority, such as a government or bank, to uphold or maintain it.
- Individual coin ownership records are stored in a digital ledger, which is a computerized database using strong cryptography to secure transaction records, to control the creation of additional coins, and to verify the transfer of coin ownership.
1.1 HODL
- In crypto, we see a lot of volatility. So, a term was commonly introduced: Hold On For Dear Life.
- It is more like an advice given to newbies in crypto that however volatile the market gets, the way to make profits from good projects is to hold on for dear life, simply put – hold on for a long time to see benefits out of it.
1.2 Transaction
- Transaction in crypto space basically means an exchange of data or crypto.
- For a transaction to take place, whether it is a transaction of data or crypto, certain gas fee is meant to be paid.
1.3 Gas fees/Transaction fees
- Miners and validators validate transactions and make sure no wrong transactions take place and hence they are rewarded for it with some crypto.
- This rewarded crypto is the gas/transaction fees, people have to pay in order to make transactions. The more gas fees you pay, the faster the transaction will take place.
1.4 Validation of a block
- Before adding any block to a blockchain, it has to be validated by nodes.
- Suppose a certain node solves the mathematical problem meant to be solved to add a new block, that block won’t be added easily to the whole blockchain.
- For every node to add it to the blockchain, each node will verify if the block is acceptable or not.
1.5 NFT (Non Fungible tokens)
- NFTs are used to represent ownership of a unique asset.
- Asset can be either a virtual land, token or an image, which can be any unique entity with only one unique owner.
- NFTs are all the hype these days. Non Fungible tokens as the name suggests are digital assets that are non fungible (non replaceable).
- NFTs have opened up a whole new industry in the blockchain space. It can be any form of digital asset, from a picture to a doodle, from a music album to a graphic design, and many more.
- Some of the popular NFTs that you must have heard of include, Bored Ape Yacht Club (BAYC), Everydays- the first 5000 days, CryptoPunks, and many more.
- But why are they so valuable? It’s their community and utility they provide that decides their worth. As in the offline world people used to invest in paintings and stuff, in this digital era people are choosing to invest in digital art.
- NFTs are more than just Digital art, they have so many use case like it can be used as a token to a community event or pass to an virtual event, used for digital land purchases in virtual worlds and for next-generation music ownership, licensing and publishing.
- In, 2021 $250 M worth of NFT transactions took place.
- The most expensive NFT was sold for $69.3 million purchase of Beeple’s historic “Everydays: The First 500 Days” bought by Sundaresan, read the full story of most expensive NFTs sold – here.
- One of the rarest is this joker-face TPunk #3442. It was sold for 120 million TRX in August 2021 to Justin Sun, CEO of Tron. This was the most expensive NFT ever sold on the Tron blockchain.
1.6 Defi
- Defi, acronym for Decentralized Finance, is basically a finance technology meant to remove the third parties from a transaction.
- It takes control of money from third parties like banks and financial institutions back to people.
- Some popular Defi include names like PanCake Swap, Aave, Colony Lab, and many more.
1.7 Mnemonic phrase
- A mnemonic phrase is a word, sentence or a poem meant to be remembered or noted down safely at the time of opening a new wallet.
- It is the only security protocol or key, you can use to get your crypto wallet account back in case you forget the password.
- Warning: If you forget this mnemonic phrase or key or password, there is no way to recover the account, as there is no central institution maintaining the same.
1.8 Staking
- The concept of staking was introduced with the consensus protocol ‘Proof of Stake’.
- Here validators stake their crypto to validate a block and are rewarded for validating correctly and fined for wrong validations.
- You need to have a certain minimum requirement of crypto to be a validator, and thus makes it hard for people to become one but this problem is solved by staking pools where people give their crypto to be combinedly staked to earn rewards.
1.9 Wallets
- Crypto wallets, similar to normal wallets, are just a means to securely store your crypto.
- They are designed in such a way that it is easy to transact but at the same time is impossible to be hacked by attackers.
- There are several security layers in a wallet and hence keeps crypto and NFTs safe.
- Most used crypto wallets are Metamask, Coinbase wallet, Binance, Ledger Nano X and crypto.com
1.10 Web3
- Web3 is a new era of the internet, a more decentralized and secure internet.
- In core essence it is – for the people, by the people, and to the people.
- It is the internet on blockchain and hence protects people’s privacy and hence provides an internet which is not controlled by a handful of people.
1.11 Smart Contracts
- Smart contracts are digital contracts written on blockchain or immutable agreements used to create a mirror of a legal agreement between two parties and stored over the immutable ledger.
- Smart Contracts are the second Evolutions for the blockchain.
- Rules written on a blockchain are automatically executed once the conditions are met.
- As smart contracts are written on blockchains, they are immutable and no changes can be made in it. But not every blockchain supports smart contracts, some that do include, Solana, Ethereum, Tezos, and many more.
1.12 P2P Network
- Peer to peer network, commonly known as P2P is a decentralized network communications model that consists of a group of devices (nodes) that collectively store and share files where each node acts as an individual peer.
- In this network, P2P communication is done without any central administration or server, which means all nodes have equal power and perform the same tasks.
1.13 Blockchain
- Blockchain is a type of DLT (Distributed Ledger technology), taking the concept of P2P network to a more secure, organized, and decentralized level, has become everyone’s source of attention.
- Blockchain is basically an immutable ledger, that is, it cannot be changed or manipulated in any way.
1.14 Fiat
- Fiat or Fiat money is a currency that lacks intrinsic value and is established as a legal tender by government regulation.
- In simple words, Fiat is the paper currency of any country like INR(Indian National Rupees) in India.
2. Introduction to Blockchain
- Bitcoin, the first Cryptocurrency and the one that brought blockchain technology to the light in 2009, was created with an aim to build P2P form of transactions.
- Blockchain technology simply explained is a chain of blocks, where blocks contain data in a way that makes the data easy to access, immutable, safer and transaction irreversible.

Image from Pixabay – Source
- Blockchain is decentralized (Keep reading you will get it), which means a copy of data is stored in every node that is connected to the network which also makes it impossible to erase or modify a transaction.
- Blockchain is a network of nodes, where nodes can be anything from a computer to a mobile phone to a laptop on that network.
- All the data is stored on every node of the network. As there are multiple copies of the data, even if an attacker manages to manipulate the data on one node, we can easily identify the attack and protect the blockchain.
- P2P network, that is ‘Peer-to-peer’ network as the name suggests refers to a network where there is no mediator or third party involved. P2P, however, refers to the distributed network, blockchain is more based on decentralization of the network. These two words are often mistaken for one another, but they are efficiently different.
- Check this video link here to find the difference between “DLT vs Blockchain vs Bitcoin”.

A decentralized system is a subset of a distributed system. Blockchain can be called decentralized in terms of its architecture and control but it is centralized in terms of its build logic. It cannot be controlled by a single entity nor can it have a central control point in its network but it does follow a single logic. Think of as, how common law works, common law is nothing but general convention accepted on the basis of precedents.
Blockchain is architecturally decentralized because it does not have a central control point, politically decentralized because no single person makes it, it is like a practice accepted by the mass, but logically centralized because it is law and is meant to be followed.
To understand decentralization better, we a look at the image below

Read more about Decentralization – Here.
What makes blockchain so secure?
Blocks in a blockchain are held in a hashed form(Secret form that is very tough to crack), that way, one cannot read it with ease but more to that each block contains
- Data,
- Block number,
- Timestamp
- Nonce (Number only used once), and
- Previous block Hash.
So, if any changes are made in a data of block, its hash eventually changes but because every block contains a hash from the previous block, all the blocks after the victim block will not correspond to the chain. hence for an attacker to manipulate data in a blockchain, he will have to make changes to all the blocks that come after the targeted block.
If someone manages to make changes to all the blocks coming after a targeted block, is it still safe? Well, even if someone manages to hack all the blocks on a node, we still have a copy of the blockchain in all the nodes of the network. So, we can compare and track for any hacks easily. Hence, it is safe to say, hacking a blockchain and manipulating data is almost impossible.
Blockchain – A Long history a twitter thread – click here to read.
3. What are Popular Consensus Protocols?
- Consensus Protocols forms the structure for a blockchain to be built-on and to implement any other function on it.
- Consensus builds the logic behind any certain blockchain and hence is the only way, blockchain in any way is centralized.
- Theories say that, the blockchain is considered compromised if a hacker gets access to more than 51% of the network. Various types of consensus protocols solve the 51% attack problem in many ways.
- Blockchain Consensus also provides the following:
- Structure on how many new blocks can be added to the chain ?
- Maintains the integrity of each new block added.
Let’s discuss some of the popular consensus protocols:
3.1 Proof of Work (PoW)
- If you have heard of any Consensus Protocol, you have definitely heard of Proof of Work.
- It is one of the first consensus protocols and also the one on which several famous Cryptocurrencies such as Bitcoin, Ethereum and Dogecoin are based.
- Proof of Work is also the most energy-hungry among all the protocols.
- A lot of computational power and energy is consumed to solve complex mathematical puzzles to come up with a nonce value that generates block hash under a pre-set conditions .
- For example, in bitcoin’s chain, for a block to be validated it has to have starting 18 digits as zeros in its 64 bits hash.
3.2 Proof of Stake (PoS)
- Proof of Stake, created in 2011, is seen as a better alternative to Proof of Work by many.
- Ethereum, one of the largest blockchain networks, is seemingly shifting from Proof of Work consensus to Proof of Stake consensus.
- In Proof of Stake, mining is done through validators staking cryptocurrencies.
- These validators are rewarded for fair behavior and penalized for wrong.
- The only disadvantage of this consensus is miners can be bribed to validate a wrong transaction.
- Some of the Top cryptocurrencies such as Solana, Cardano and many more are currently based on the Proof of Stake consensus protocol.
3.3 Delegated Proof of Stake (DPoS)
DPoS, often known as democratic version of Proof of Stake. Here, a voting system is implemented to choose a validator to help in the validation of the new block. Other than validating new blocks, these validators will also help in validating transactions and in the process they will be rewarded with a transaction/gas fee. Delegated Proof of Stake protocol can also manage higher transactions per second (TPS) than Proof of Stake and can also quicker in performing and completing a transaction. Recently , DPoS is being used as a consensus protocol for blockchain projects like Bitshares, Steem and Tezos.
3.4 Proof of Elapsed Time (PoET)
Intel created Proof of Elapsed Time consensus protocol to be used in permissioned
blockchain networks. Now the way permissionless and permissioned blockchain networks
differ from each other is that you need permission to use a permissioned blockchain, while you don’t need any kind of permission to use permissionless blockchains. The two systems might sound similar, but they cannot be used for the same things. In PoET, each node is allotted a random waiting time, where the block which first completes the randomly chosen period, validates the block. Also, here anonymity is not a feature to anyone.
3.5 Proof of Authority (PoA)
Conceptualized by the co-founder and former CTO of Ethereum, Gavin Wood in 2017, Proof of Authority, as the name suggests, is a consensus where blocks are validated on the basis of the miner’s authority. Here, instead of cryptocurrencies, validators stake their reputation and authority to validate a new block and transactions. It is a perfect consensus protocol for private blockchains. PoA is also an easy-to-scale system for any blockchain as it works on a fixed number of block validators.
3.6 Proof of Space (PoSpace)
Proof of Space is somewhat similar to Proof of Work, but instead of work, here we validate a new block or a transaction on the basis of the disk space of the validator. Here, miners are incentivized on the basis of the disk space they allocate to a block. This consensus protocol is not very fair as it goes against the point of decentralization, as mining here is resource-biased. Projects like Burstcoin and SpaceMint are based on the Proof of Space consensus protocol.
3.7 Proof of History (PoH)
Proof of History consensus protocol came to light when Solana implemented it along with Proof of Stake to come up with a different consensus protocol. PoH makes transactions very fast and efficient as it does not require any validator or energy to validate a block. In PoH, timestamps are recorded for every transaction and combined with the transaction, are hashed and stored in the blocks. Every new block other than its own hashed form of transaction and timestamp contains the hash of the previous block. So, if any changes are made in any block by an attacker, its timestamp will change and hence, its hash won’t match with any next block. This feature of timestamps makes this consensus so secure and fast.
4. What are Whitepapers?
Whitepapers are the official documentation of any Crypto-Project. They shed light on the technology the project is based on and the scope and motive behind the project. It gives blockcchain technology enthusiasts and investors an idea of the of a project. Whitepapers contain the use-case, the future growth, time-lines of the project, and historical data/challenges of the use case . Bitcoin being the most popular crypto project, had one of the first whitepapers to be published in the crypto space, and that way, also the most read whitepapers. Whenever researching any certain project, it is crucial to read the whitepaper to know about the project in-depth. In short, a badly written whitepaper acts as a repellant, whereas a clearly written and easy-to-understand whitepaper works very efficiently. So, if you someday wish to start your own crypto project, be sure to make the whitepaper in an easy-to-understand manner, maintaining transparency.
Have a look at the following articles on whitepapers for Blockchain and Cryto:
- Top Whitepapers in Crypto and Blockchain – check it out here.
- Satoshi & Company: The 10 Most Important Scientific White Papers In Development Of Cryptocurrencies – click here.
5. Popular Blockchains in the industry
Several blockchains projects are now in the crypto space. Some are private, some are public, some are permissionless, some need permission to use, with each blockchain working on different logics and consensus, they are mostly different. Blockchains are nowadays implemented in several platforms, many use already existing ones, many build their own blockchains. With the rise in companies in Blockchain-as-a-service (Baas) space, blockchain technology is now the center of every tech entrepreneur’s attention. Currently, there are estimated to be over 30 popular blockchains in the market.
Let’s discuss some of the popular blockchains in the industry:
5.1 Bitcoin
The most popular and the first blockchain to be introduced is Bitcoin. Created in 2009, bitcoin brought a whole new concept of digital currency at the foot of an economic recession. We do not know who invented or created it but an alias has been given to the person or organization that created Bitcoin, Satoshi Nakamoto. Bitcoin being the biggest cryptocurrency has a market cap of over 350 billion dollars even in this downtrend of crypto.

Image from Pixabay – Source
It is the most trusted, secure and biggest cryptocurrency out there. It does not support smart contracts to be built on it. As Ethereum is often referred to as the internet of blockchain, bitcoin is referred to as its gold.
5.2 Ethereum
It is widely known in the crypto space, that if Bitcoin is the gold of the crypto world, Ethereum is the Internet. Ethereum was created by a famous Crypto billionaire (billionaire due to Ethereum) in 2015 when Bitcoin’s developers rejected his idea of allowing apps to be built on the blockchain.

Image from Pixabay – Source
Vitalik Buterin, one of the contributors of the Bitcoin codebase built a new chain by considering the limitations of bitcoin. This second public blockchain is called Ethereum. Ethereum has the functionality of smart contracts that can automatically perform logical operations based on a set of criteria established in a blockchain.
His story is very much like if you can’t get your way, make yourself a different road. Ethereum is now being widely adopted by many blockchain developers to make their own dApps (decentralized applications). Ethereum was the first blockchain that allowed people to build smart contracts on it. A majority of big Crypto Projects run on Ethereum, and it has gained investments from several crypto billionaires and tech giants. It also has the biggest developer community and its own programming language called Solidity. With its defined rules and easy-to-use format, it has revolutionized dApps in the blockchain technology.
With the scarcity of developers we have in the industry, many of them already being Ethereum developers, many projects in the initial stage have to operate on Ethereum only because it’s very tough to find good blockchain and smart contract developers. But having such a big community is also a bad thing for Ethereum, because the network keeps on working on 100% capacity, it’s easy to get overloaded. So, nowadays scalability has been a major issue with Ethereum. With so many transaction requests in the network, the transaction speed has been very slow, topping the troubles with a high gas fee (transaction fee). Even after this, Ethereum’s big community is the reason for its quick growth and it still has the potential to grow more, as developers are working on ways to improve the platform’s scalability.
5.3 Polkadot
Polkadot was created by Ethereum’s Co-founder, Gavin Wood in 2016. Gavin Wood, with Web3 foundation, designed Polkadot with a total initial supply limit of 10 Million coins. When its ICO (Initial Coin Offering) was launched, 5 million coins were sold up right away, collecting over 140 million dollars worth in Ethereum. This ethereum was then stored on a cold wallet which was made by Parity, also a company by Gavin Wood. But in an accident with the wallet, 60% of the ethereum was said to have been locked away in 2019. But to recover those losses, more ICOs were organized, and their value was stabilized.
Polkadot Image by Author
Polkadot also is a contender for becoming the Ethereum- killer, as it is more scalable and has a low transaction fee. It works on the Proof of Stake consensus protocol. Polkadot is one of the very unique blockchains, even Ethereum 2.0 might implement some of its concepts. Polkadot’s supply can also be increased to even 1 billion, based on the votes of the stakeholders. Polkadot is more of a blockchain ecosystem where various platforms are connected to each other, rather than a blockchain in the traditional sense. Polkadot, being so unique that it is, has yet to achieve its full potential. With projects like RMRK, Moonriver, Moonbeam, Acala working on Polkadot, it has an amazing growth opportunity moving ahead.
5.4 HyperLedger Fabric
Anonymity is not always desired while working with some highly important data. This is where HyperLedger Fabric comes in. In 2015, Linux Foundation, with 30 other co-founders, such as IBM, Cisco, JP Morgan, Intel, and others, created HyperLedger Fabric, which is a permissioned blockchain network. Now, one might ask, what is a permissioned blockchain? As already explained above, the very simple explanation includes that you need permission to access this blockchain network, but there is more to that.

Image from Pixabay – Source
In permissioned blockchain, your identity is authenticated for you to access it. It is great to work on sensitive data transactions. HyperLedger Fabric has to comply with data protection laws, which makes it more safer for transactions. The platform users can create private channels for particular network members, meaning that only selected participants can access transaction data. However, it requires a hardware system to ensure a higher level of security. HyperLedger, very much like Ethereum, is very user-friendly.
5.5 Tezos
Protocol Forks has been a big problem with many blockchains for quite a long time. Protocol Forks refer to a split that happens in a community when a new set of ideas has to be implemented to the blockchain’s basic set of ideas. When this happens, the chain produces a second blockchain that shares the same history with the previous chain, but now is a different chain of its own. This is the reason why Bitcoin has so many forks, including Bitcoin cash and Bitcoin SV. As a solution to this problem, Arthur Breitman created Tezos in 2017.

Image by Author
To avoid forks, Tezos works on a on-chain self-amendments protocol. According to this, protocols can be automatically upgraded if the majority of the stakeholders vote in favor of certain improvements proposed by any developer. This arrangement makes Tezos grow well because developers are constantly working on improvements. Tezos has seen a surge in popularity in the last couple of years. Staking, however, can be hectic and money blocking to some people due to lack of liquidity. But in Tezos, Liquid Proof of Stake is implemented that allows stakeholders to unstake anytime they want, i.e. No lock-up period. There is no doubt that Tezos is also a contender to be Ethereum-killer.
5.6 Stellar
Stellar can simply be explained as a specialized transaction blockchain. It is the simplest of all the blockchains in this list but still better than many in terms of safety in transaction, in terms of transaction speed, and scalability. Stellar was created in 2014 by Jed McCaleb, who also founded Ripple. However, focussing on such a narrow scope alone also happens to be the reason it is so good for transactions.
Stellar is even trusted by IBM as they have chosen Stellar to create World Wire, a global payment system set to streamline cross-border money transfers. Being such a simple blockchain Stellar does not have its own coding language to write smart contracts on, and is liked by many developers because of its interoperability on different platforms.
Stellar has several layers of security and hence is safer. It can have a multi-signature batching system which makes it the best choice for any organization that needs to come up with a simple and effective smart contract.
5.7 Solana
Solana is not only one of the biggest contenders to be ethereum-killer but also the only smart contract platform currently available to us that can give big companies like VISA, a run for their money, in terms of transaction scalability. Solana was created by top software engineers from Intel, Dropbox, and Qualcomm in 2017. There are several blockchains that are trying to come up with a solution to the scalability problem and tackle the issues, but Solana is leaps ahead in this race.

Image by Author
Solana works on a combination of Proof of Stake and Proof of History protocols. Currently, it can easily have around 50 thousand transactions per second (TPS) on the platform. But is it the maximum limit it can reach? Absolutely not, developers say that Solana has the potential to even reach more than 700 thousand transactions per second which is a huge number compared to ethereum’s 15 TPS or Visa’s 24000 TPS. As more people join and invest in Solana, it will reach closer to its upper bound number. Solana is not just a transactional scalability solution to many of the problems but also solves the financial scalability of blockchains as it requires very less transaction charges (or gas fees).
Applications using Solana. Does Solana exist now?
Solana is still in its initial stage and has a lot of potential to grow more. Several big projects are also being established on its ecosystem including :
- Solsea (an NFT minting platform on Solana)
- Solanium (a platform to find Solana projects and invest in a crowdfunding manner), and
- Many other DApps like Audius and more.
5.8 Avalanche
Without any doubt, Avalanche is one of the most popular blockchain networks available to us these days. Created by Ava Labs, Avalanche was launched in September 2020. The platform’s public token sale raised $42 million in 4.5 hours, which is a big number in such a short period of time. Avalanche works on Delegated Proof of Stake (DPoS) consensus protocol. Being on DPoS, it is a bit tougher to become a validator on its network. But even so, there are several validators staking on Avalanche which shows that it is a promising project to have gained so much support in the little time it has been in the market.
Avalanche also is a great alternative to ethereum as it works on lesser gas fees and has a better scalability and can go as high as more than 4500 TPS, making it also a contender to one day compete with transaction giants such as VISA. In DPoS model, you can also delegate your stake to other validators to earn yield as well.
Projects for Avalanche
Avalanche is also a great choice for several DApps developers as evident from some big projects such as BenQi, Trader Joe, Pangolin, YieldYak, and many more working on its ecosystem.
6. Safety from Crypto Scams
With so much potential, there also are several risks involved with blockchain tech related projects. In October 2021, a scam worth more than 3 million plus dollar took place which is also called as Squid Games Scam, check this video here to read more on Squid Games Scam and how How to identify fake cryptocurrency? And how to be smart enough to avoid being scammed.

Image from Pixabay – Source
Scammers won’t stop trying to harm us but we have to get smarter in order to not get tricked. The best way to not get tricked and scammed is by gaining knowledge. Knowledge about the tech, about the projects, about the market should be gathered before diving into any project.
5 key points to remember to always be safe:
- Keep your wallet’s mnemonic phrase safe.
- Don’t connect it with just any platform before checking what access you will be giving while connecting.
- Make reading whitepapers a habit while exploring any project.
- Analyze how long the project has been in the making and who are the founders.
- Look into the future possibilities of the market and make your decision wisely.
7. Conclusion
The developments in Blockchain Technology, Metaverse, NFTs, Cryptocurrencies, Defi, clearly has overwhelmed the world with so many new concepts and technologies, to an extent that people even refuse to believe that it is possible. But it was the same when the Internet was first introduced, the same when the World Wide Web was introduced, the same when smartphones were introduced. New technologies often take time to be accepted by the world but as happened in the past, people will eventually get normalized to it. As more people get educated in the field, more improvements and new tech will be introduced, which will eventually make it more accessible to the people. (the reason why we wanted to research a lot and share this Blog with you to read and get benefitted! )
Right now, even with the few thousands of blockchain developers, the tech has developed a lot. People being skeptical of new things is expected, but let us take an example: Do you worry about the medicines your doctors give you when you are sick? No, because you know that they are qualified for it and hence you trust them.
Now, big companies like Microsoft, IBM, Facebook, Alibaba are taking interest in blockchain technology and some big shots even openly say that they see high potential for Blockchain tech in the future. Well, they are knowledgeable enough to say this. So, instead of being skeptical, we should learn, acquire knowledge, and work together to make the best use of new age technologies like Blockchain technology.
If you liked this Blog, leave your thoughts in the comments section, See you again in the next interesting blog!
Happy Learning!
Until Next Time, Take care!
– TheHackWeekly Blog By Vedaang
Checkout our Blog on “Comprehensive History of AI: First AI Model to Latest Trends” – here !p
The post Blockchain Technology for beginners first appeared on TheHackWeekly.com.
]]>The post Top 10 Python Functions to Automate the Steps in Data Science first appeared on TheHackWeekly.com.
]]>
Parameters have a positional nature by default, and we have to inform them in the same order in which they were defined.
Making a Function Call
A function is defined by:
- Giving it a name,
- Specifying the arguments that must be included in the function, and structuring the code blocks.
Once a function’s fundamental structure is complete, you can call it from another function or directly from the Python prompt to run it.
3. Automation
The process of automating the tasks of applying machine learning to real-world issues is known as automated machine learning. From the raw dataset to the deployable machine learning model, Automated machine learning covers the entire pipeline and is offered as an AI-based answer to the ever-increasing issue of machine learning applications. Automated machine learning’s high level of automation enables non-experts to employ machine learning models and techniques without having to become machine learning professionals.
Automating the entire machine learning process has the added benefits of:
- Providing simpler solutions,
- Faster generation of those solutions, and models that frequently outperform hand-designed models.
In a prediction model, Automated machine learning was utilized to compare the relative relevance of each factor.
4. Let’s compare to the standard approach
Data Scientists in a typical machine learning application have a collection of input data points to train with. The raw data may not be in a format that can be used by all algorithms. Data Scientists need to use the following to make the data suitable for machine learning:
- Proper data pre-processing,
- Feature engineering – feature extraction and feature selection.
Following these, they must choose an algorithm and optimize hyperparameters to improve their model’s prediction performance. Each of these phases might be difficult, making machine learning difficult to implement.
Automated Machine Learning substantially simplifies these tasks!
5. How to automate boring stuff and save time?
There is a saying doing a smarter way is more impactful than doing the hard way. You are a data scientist in XYZ company, you have been assigned to develop a product for your organization having x objectives. So, whenever you are designing the architecture of the data science project in your workspace; you have to do the following tasks such as importing data, data preprocessing, building machine learning models, performance measurement of models, deployment, and much more.
In a typical end to end project, there are many ways, 2 common ways are,
- You will be having a compressed data file.
- The data will be stored in a relational database having multiple tables/ documents/ files.
In both instances, you have to gather the data, perform data preprocessing, and built the model in which you have to write the same sorts of multiple lines of code.
In this blog we will be discussing the following in context to function:
- Focusing on Data and Training
- Performing EDA (Exploratory Data Analysis)
- Building Machine Learning Models
- Prediction
- Model Deployment
5.1 Focusing on Data and Training
If you are assigned a task to build a model the first thought comes to in mind:

Let’s concentrate on what is both and how it is significant:
1. Batch Learning
- The system cannot learn gradually in batch learning; it must be trained to utilize all the available data because this takes a long time and a lot of computing power, it’s usually done offline.
- The system is first trained, and then it is put into production, where it operates without having to learn anything new; it simply applies what it has learned. This is referred to as “offline learning.”
- Unless you want a batch learning system to learn about new data (such as a new type of spam), they must first train a new version of the system from scratch on the entire dataset (not just the new data), then terminate the old one and replace it with the new one.
- Moreover, the entire process of training, testing, and releasing a Machine Learning system can be automated, allowing even batch learning systems to adapt to changing conditions. Maintain current data and retrain a new version of the system when needed.
- Furthermore, training on the entire collection of data necessitates a significant amount of computer resources (CPU, memory, disc space, disc I/O, network I/O, and so on). It will cost you a lot of money if you have a lot of data and you automate your system to train from scratch every day. It may even be impossible to employ a batch learning method if the amount of data is enormous.
2. Online Learning
- In online learning, the system is progressively trained back to back giving it data instances, either individually or in small groups known as mini-batches. Each learning phase is quick and inexpensive, allowing the system to learn about new data as it comes in. For systems that receive data in a continuous stream and must adapt to change quickly or autonomously, online learning is ideal.
- Online learning methods can also be used to train systems on massive datasets that are too large to fit in the main memory of a single machine (this is called out-of-core learning). The algorithm loads a portion of the data, performs a training step on that data, and then continues the process until all of the data has been processed.
While building batch learning as mentioned above it has to be trained with available data to do so here is the below code.
Note: All CODE BLOCKS are BEST viewed in DESKTOP MODE, kindly switch for BEST experience!
As we have to work on available data so no such automation is required and it is a one time process, however, if you want to train the model progressively for example in the stock price sector you need to update the data in each instance that is a type of online learning as mentioned above:
5.2 Performing EDA (Exploratory Data Analysis)

Exploratory data analysis, or EDA for short, is a term coined by John W. Tukey for describing the act of looking at data to see what it seems to say. It assists data scientists in determining how to best manipulate data sources to obtain the answers they require, making it easier for them to find patterns, test hypotheses, and verify assumptions.
EDA is primarily used to examine what data can disclose outside of formal modeling or hypothesis testing tasks, and to gain a better knowledge of data set variables and their interactions. It might also assist you in determining whether the statistical techniques, you’re contemplating for data analysis are suitable.
Why EDA?
The primary goal of EDA is to assist in the analysis of data before making any assumptions. It can aid in the detection of evident errors, as well as a better understanding of data patterns, the detection of outliers or unusual events, and the discovery of interesting relationships between variables. Exploratory analysis can be used by data scientists to guarantee that the results they create are accurate and appropriate to any targeted business outcomes and goals. EDA also assists stakeholders by ensuring that they are asking the appropriate questions. Standard deviations, categorical variables, and confidence intervals can all be answered with EDA. Following the completion of EDA and the extraction of insights, its features can be applied to more advanced data analysis or modelling, including machine learning.
Types
There are 4 primary types of EDA:
1. Univariate
This is the simplest method of data analysis where the data being investigated only has one variable. Because it is a single variable, it does not deal with causes or relationships. The basic purpose of the univariate analysis is to describe and detect patterns in the data.
2. Univariate with graphs
Single variable Visualisation to seek more information and patterns. As a result, graphical methods are required. Common types of univariate graphics include:
- Stem-and-leaf plots
- Histograms
- Box plots
3. Multivariate
Multivariate data arises from more than one variable. Multivariate EDA techniques generally show the relationship between two or more variables of the data through cross-tabulation or statistics.
4. Multivariate with graphs
Graphics are used to demonstrate relationships Other common types of multivariate graphics include:
- Scatter plot
- Multivariate chart
- Run chart
- Bubble chart
- Heat map
To do so we can create a python function:
In python, pandas have an in-built function to look and understand the attributes, sometimes it will be too clumsy to write each line of code and run it, here is how you can write a function to make work easier.
However, pandas_profiling and sweetviz are two libraries that perform exploratory data analysis with few lines of code. Also, once the EDA is done, data preprocessing and cleaning is initiated that will comprise of but are not limited to:
- Conversion of Categorical Data into Numerical ones
- Replacing missing values or unwanted values
- Removing Outlier
- Scaling or Normalization of data
NOTE: Business Context should be taken into consideration while performing the above measures.
5.3 Building Machine Learning Models
Machine learning (ML) is a sort of artificial intelligence (AI) that allows applications to improve their prediction metric over time without being expressly designed to do so. In order to forecast new output values, machine learning algorithms use historical data as input.

Building a machine learning model is a strenuous exercise, each time you have to start from scratch, with the use function you can simply pass whichever model you want to work on.
Why?
Whenever you are building a model each time you have to write the same few lines of code, this will be going to fetch extra seconds, these seconds could be used to improve model performance in different ways.

However, in the above model function, I am just returning the accuracy of each model, we can return other performance metrics also. Such as in the case of the classification model:
In the above scenario, as it is a classification model precision, recall and F1-score is returned as seen in the below output:

5.4 Prediction

When estimating the likelihood of a given result, such as whether or not a customer would churn in 30 days, “prediction” refers to the output of an algorithm after it has been trained on a previous dataset and applied to new data. For each record in the new data, the algorithm will generate probable values for an unknown variable, allowing the model builder to determine what that value will most likely be.
The term “prediction” can be deceptive. In some circumstances, such as when utilizing machine learning to pick the next best move in a marketing campaign, it means you’re forecasting a future outcome. Other times, the “prediction” concerns, for example, whether or not a previously completed transaction was fraudulent. In that situation, the transaction has already occurred, but you’re attempting to determine whether it was legitimate, allowing you to take necessary action.
Why are Predictions Important?
Machine learning model predictions allow organizations to generate very accurate guesses about the likely outcomes of a query based on historical data, which might be about anything from customer attrition to possible fraud. These supply the company with information that has a measurable business value.
For example, if modelling predicts that a client is likely to churn, the company can reach out to them with tailored messaging and outreach to prevent the customer from leaving.
To do so we can create a python function
Key Takeaways are
- Basics of Reusable Python Functions
- Automation Significance
- Batch vs Online Learning Understanding
- Exploratory Data Analysis Understanding
8. Benefits of employing Python functions
- Reducing code duplication
- Taking big problems and breaking them down into smaller chunks
- Increasing the code’s clarity
- Reusability of code
- Readability of code
- Information is being kept hidden.
9. Conclusion
With the continuous inflow of data in the world, in fact, all the sectors whether it be finance, sports, marketing, supply chain or social media, the task of data scientists have been increasing drastically and the challenges increase more if you are a solo data scientist in your firm. The development of machine learning products has become more complex than ever due to the increment of volume and varieties of data. Working with data is tedious work and doing the same sorts of code, again and again, can affect the quality.
With automation, the following benefits can be achieved:
- Time Management: You can easily segregate your time where to invest and how much, with the above codes you have to only pass several models, the other tasks can be automated.
- Trade-off: There is always a trade-off about how much time you want to invest in Exploratory Data Analysis as it is a never-ending task when the data is on a larger scale, with automation you can easily pass the features or call the function to do so.
- Business Insights: Time is money, with getting more minutes in your bucket you can drill down more into the data to get deeper business narratives or insights.

With the usage of the above code snippets, you can develop a package for the XYZ Team and that could be used by all of the members of that team and help in automation.
If you liked this Blog, leave your thoughts and feedback in the comments section, See you again in the next interesting read!
Happy Learning!
Until Next Time, Take care!
– By Swetank
Most Viewed Blog in our website is mentioned below:

The post Top 10 Python Functions to Automate the Steps in Data Science first appeared on TheHackWeekly.com.
]]>The post Logistic Regression: Best Walkthrough With Python is Here Now first appeared on TheHackWeekly.com.
]]>
1. Logistic Regression – Introduction
We are going to start with what logistic regression is?
- Logistic Regression, is used in statistics to estimate (guess) the probability of an event occurring provided we have some previous data, which means to predict a data value based on prior observations of a data set.
- Logistic Regression works with binary data, where either the event happens (1) or the event does not happen (0).
- It is named ‘Logistic Regression’ because its underlying technique is quite the same as Linear Regression. It is a simple machine learning algorithm that is most commonly used for classification problems in the Industry.
Note: The main aim of the blog is to get you to code and use it in predictions while knowing the theory behind it, so you don’t miss out on both theory and practical coding.
From here, the first question that comes to our mind is, what’s wrong with linear regression for a classification problem, Right?
Well, there are a couple of problems and let’s discuss them briefly:
1.1 A slightly far off input disturbs the entire algorithm
I will explain this with a hypothetical scenario. Imagine a problem where we are to predict whether a tumour is benign or malignant. In that case if we plot a best fit line using linear regression then it will look somewhat like this.

Clearly from here, you can say that the best fit line is not a good threshold to predict whether a tumour is benign or malignant. This is a simple way to understand why linear regression is not suitable for classification tasks as the inputs are in zero and one.
1.2 The predicted value of y is much larger than 1 or much lower than 0
Now we have established why linear regression fails for classification problems, so let’s get straight into logistic regression. Before we do anything, we have to first understand how to interpret the output from the logistic regression model.
This logistic regression model will predict a output between the range of 0 and 1, 0 < y_pred< 1.
Here, y_pred is the estimated probability of getting y = 1 if the input is x.
For example:
Suppose the value of y_pred is 0.9, then its interpretation is that the probability of y being 1 is 90%.
Mathematically, hθ (x)= P(y=1| x ;θ), hθ (x) = y_pred
Symbols used: _ (underscore) means subscript and ^ (power cap) means superscript
2. Computing the Predicted Output
Now with all that being said, let’s compute the predicted output. We will start this quest by taking a look at the logistic regression equation.

Here x1 and x2 are the input features. For example, let’s say we are predicting whether a tumour is malignant or benign, then x1 will be the area of the tumour and x2 will be the perimeter of the tumour. There will be many more input features as well but first we will continue with these two features.
Next comes w1 and w2.
These are the weights associated with the logistic regression model. The input value is fixed for a particular datapoint, so the only way to change the value of the output is by tweaking the weights and the biases ( bias is the term b here, but we will discuss that later ) only.
For example,
If our model is predicting the output probability to be 0.10, which is suggesting that the probability of the tumour being benign is high, but in reality it is malignant, then we can change the value of the weights and biases to make the output probability to be above 0.5.
Now what should be the initial value of the weights ? We can initialise the weights to be of any value from negative infinity to positive infinity in theory, but for practicality we have to keep in mind a few things. What are these few things ? We will discuss that a little later. But for now keep in mind that we should not initialize the weights very high or very low. It can be around the range of [-0.5,0.5] or [-1,1] or (0,1].
Now we will discuss the bias or the term b in the equation. Bias is added to the equation so that the decision boundary does not pass through the origin every time. It is much like the y-intercept in the equation of a straight line. If the y-intercept is not present or is zero then the line always passes through the straight line. It is generally initialized with the value of zero but its value changes to some random number that gives the best output after gradient descent ( we will discuss gradient descent in depth in this article as well ).
Now we jump into the next step of computing the predicted output. As you can imagine, all these values like x1 , w1 , etc have random values and therefore the value of z will not be in the range of [0,1] or [-1,1] ( considering -1 to be the opposite case ). So we pass this value of z to a function known as activation function which decreases or increases the value of z to the range of [0,1] or [-1,1] and that we can accept as our predicted output. I will discuss some activation functions and that will make things clearer.
2.1 Sigmoid Activation Function
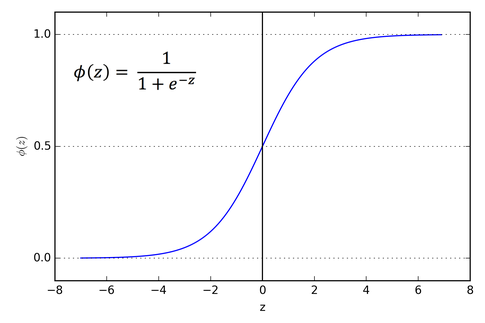
The sigmoid activation function looks somewhat like this : φ(z) = 1/(1+e^(-z))
If you compute the range of the function you will find it to be (0,1). And for z = 0 the function returns 0.5. The behaviour of the function will be more clear from this Graph.

Image courtesy
{kind=link}
The graph shows that if the value of z is very low then the output is generally zero and if it is very high then the output is generally one. From here we can also get a idea that if the value of the weights are very low then the value of z will be very low and therefore the output will always be very close to 0 and when the value of the weights are very high then the value of z is very high and the output will always be one. This is one of the reasons why the value of the weights should not be in extremes.
2.2 Tanh Activation function
The Tanh activation function equation looks something like this :

Image courtesy
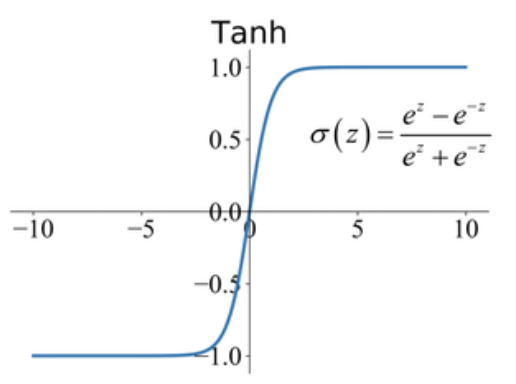{kind=link}
It is very evident from the graph that the range of the tanh function is between [-1,1] and has a value of 0 at z = 0. Also the nature of sigmoid and tanh curve are quite similar. Now a question arises if we have Sigmoid then what is the need of tanh ? In case of tanh the data is centred around zero and the negative inputs will be mapped strongly negative and the positive input will be mapped strongly positive.
5 most used Activation functions are
- Sigmoid activation Function: Equation – φ(z) = 1/(1+e^(-z))
- Tan h activation Function: Equation – σ(z) = ((e^z – e^(-z))/(e^z+ e^(-z))
- ReLu activation Function: Equation – y = max(0,x)
- Leaky Relu activation Function: Equation – y = max(0.01*x,x)
- Softmax activation function: Equation – softmax(x_i) = e^x/∑_j e_j
Finally we have summarized the entire process through this image. Take a look at this for getting the complete picture.

3. Understanding Loss and Cost Function
We have our predicted output in our hand right now and also the original output from the data. But we realise that our model has not done a very good job and has got most of the predictions wrong. After thinking a little we realise that this is quite certain as the weights and biases had absolutely no correlation to the original output. So we now want to convey to the model that it has performed very poorly and for that we need something to quantify the mistake of the model. This is where the loss function comes into the picture. There are many loss functions out there but the two that are mostly used are Mean Squared Error loss function, about which you would probably know if you have studied Linear Regression and the second one is Cross Entropy Loss function which is used in case of Logistic Regression and we will discuss that here.
I will start explaining cross entropy loss function directly from the equation:

Here, y = original output and y^ = predicted output.
We know that original output or y can have only two values either one or zero, for example the tumour can be either benign or malignant.
If we plug y = 0 in the above equation it reduces to : Loss = -log( 1-y ̂) whose graph looks somewhat like this:

Therefore, if the model predicts 1 while the true label is 0, then according to the loss function the error is infinity and as the prediction approaches 0 from 1, the error gradually decreases and finally, if the model predicts 0 then the error is zero as the true label is zero.
And if we plug y = 1, then the equation reduces to -log(y ̂), whose graph looks somewhat like this:

Here, if we analyze this graph we will find out that when the predicted value of y is 0 and the true label of y is 1, then the error is again infinity as the prediction is completely wrong and as the prediction approaches 1 from 0, the error will gradually decrease and will finally become 0 if the predicted value is 1 which is also the true label. Mind you, the predicted output is basically a probability and will be any value between 0 and 1, not exactly 0 or 1.
With this we have got an idea of how the loss function actually works, how it is able to actually tell the model about its performance but all this discussion above was about one data point and now we will have to extend this entire thing for all the data points and compute the overall loss so we can get a better picture of how the model is. For this we introduce something known as the cost function. In the cost function, we take the sum of all the losses from all the data points and then divide it by the total number of data points. I will introduce the equation of the cost function and it will make it clearer.

In other words we take the average of all the losses that we computed from all the data points. I hope this entire thing made some sense. If not, then I will suggest you to read this again or take a look at some other articles and lectures for clarity. Here we end our discussion about the cost and loss function and we will move onto the next step.
Some of my suggested lectures and blogs are:
- Youtube Video on logistic regression – Here.
- Youtube Video on cost function – Here.
- Coursera course – Here.
4. Optimising Weights Using Gradient Descent
After we are done computing the loss and the cost function, we now have to reduce the value of the cost function ( Not if we have a very less cost in the first attempt itself, but that is almost impossible). So now is the time to change the weights properly so that the
predicted output is close to the original or true output and therefore the value of cost function is reduced or can be minimised as much as possible. For this we will be using the gradient descent algorithm. The aim of gradient descent is to optimise the value of all the weights which in this case is w1 and w2 and the biases as well.
The gradient descent algorithm looks somewhat like this:

Here, w1 = one of the weights in the model
:= is update equals
α = learning rate
j = cost function
Until now, we knew that cost function is a function of y and y_pred, but I have written it to be a function of y and w1. This is because y_(pred )is a function of w1,w2 and b but we will consider w2 and b constant for this case and we will do partial differentiation with respect to w1. That is why I have written it to be a function of w1.
If we plot the graph of cost function with w1 or weights of the model, we will find out that it is a parabolic curve just like the one shown below. I am skipping the mathematics of it in this article. Now, we know that taking a derivative is basically drawing a tangent at a point in the curve where the derivative is taken. With all that being said, let’s start breaking down the gradient descent equation. w1 is the initial weight that is the one we initialised. Let’s assume that w is the point for which the graph will have its minima and w1 is a point on the curve which is not equal to _w, therefore j(y,w1)> j(y,▁w). Refer to the graph below if you are having problems with visualizing.

Image courtesy
Now, if we take derivative ( we are taking the derivative as in the equation of gradient descent we need the derivative of cost function ) at w1, the value of the derivative will be positive. Why ? This is because tanθ,where θ is the angle made by the tangent with the x-axis therefore is acute and so tan θ will be positive. α,Here is the learning rate which is positive and is generally less than 1. I will discuss its significance a little later.
Now, the equation looks something like this: w1 := w1 – (positive number)*(positive number) ,
that is the value of w1 will slightly decrease and will be updated. Now this entire process will continue until the minima is reached where the value of the derivative will be zero and so w1 will not change anymore. If the value of α is high then the value of w1 might get lower than w_ was we are subtracting a big number from w1. So, if we keep the value of α high then it might overshoot the minima and the minimum point may never reach instead we get to a point where the cost increases than before.
Now if we keep the value of α very small then the number getting subtracted from w1 will be very small and we will take a very small step towards the minima. The steps will get even smaller as we reach closer to the minimum as the value of the gradient there is also very small. Therefore it will become a very very long process. To tackle this kind of problems with the Gradient descent we have made some modifications to the gradient descent algorithms, which I will not discuss in this article but feel free to research about them. In reality we generally fix a number of iterations like 500 or 2000 for gradient descent after which we stop it.
This entire process is repeated for all the weights and biases until we get the minima for all of them.
I hope I was able to show you the beauty behind logistic regression. It might be a little difficult to grasp the entire thing in one read if you have never studied any of these things before. But hopefully, if you persist and read it a few more times, it will get clearer.
5. Coding Logistic Regression from Scratch
We have understood the Theory of logistic regression, but now we want to use it in practice.
First, let’s build a logistic regression model completely from scratch to make predictions on fake data and then we will use the scikit- learn library to build a logistic regression model and make predictions on the same data and will finally compare the accuracy as well.
In the code below, you can also visualize how the values from the cost function changed as weights and biases were changed. I have also included a decision boundary to give you an intuition about how the predictions are done
However, I have not done any feature engineering or data visualization or parameter optimization. In case you are interested in improving the accuracy than what we have got, try doing some optimisations and feature engineering.
6. Theory of Neural Networks
6.1 Computing output of a single layer Neural Network
Now we have understood the working of a logistic regression model and we will use that knowledge to get through to a simple neural network. A neural network is nothing but many logistic regression units connected to each other in different layers. Like in this case, the hidden layer has 3 Logistic Regression units and they are attached to each other. Now we will dive in to see how to compute the output of this neuron below.

Image by Author
Each Lr unit is represented like this :- a_y^([x]), here x is a number that represents the i^thhidden layer which in this case is 1 as there’s only one hidden layer and y is the i^th neuron in that hidden layer, like for the first one ( from the top to bottom ) the value of y will be 1 for the second one will be 2 and for the third one will be 3.
The first one will be represented as a_1^1, second one as a_1^2and the third one as a_1^3.
The function of these neurons in the hidden layer is to pass a value to the neuron at the output layer. Then in the output layer also, a logistic regression unit is used to compute the output.
The y_(pred) is calculated like this:
the weights in this case are not similar to the weights that we used initially during the calculation of the neuron units in the hidden layers. I hope this gives a good intuition of how a prediction is computed in an artificial neural network. The example that we have taken here is one of a shallow neural network but as we increase the number of hidden layers, a deep neural network is formed.
6.2 Backpropagating for optimizing weights
Once we are done computing the predicted values, again it is time to calculate the cost function for the neural network to see how accurate our neural network is. A cost is calculated for all the logistic regression unit in the neural network and then the derivative of the function j(θ) is taken with respect to w_i to find the best value of w_i.
The entire mathematical calculation for the back propagation of neural nets is a little bit complicated and therefore we are not discussing it here but we will try to cover it in upcoming blogs.
And with this we end the theory of neural networks. I hope this has given some clarity about the behind the work of neural networks.
To code a neural network we will need a library like tensorflow or pytorch. Although it is absolutely possible to code it from scratch using numpy and pandas but that is too complicated and we will have to compute the derivative of many functions, that is why we will be needing pytorch or tensorflow. How I wish to make a blog that discusses the matrix way of looking at neural networks and then cover the code part of it.
7. Conclusion
I hope the blog has given you a good idea about logistic regression and how it works.
The blog has taken you from understanding the processes and calculations behind the logistic regression algorithm and giving a brief demo how to use it practically to the basic working of neural networks. What goes behind a neural network and what are calculations involved in it.
If you liked this Blog, leave your thoughts and feedback in the comments section, See you again in the next interesting read!
Happy Learning!
Until Next Time, Take care!
– By Sayantan
The post Logistic Regression: Best Walkthrough With Python is Here Now first appeared on TheHackWeekly.com.
]]>The post A Comprehensive History of AI is here: First AI Model to Latest Trends first appeared on TheHackWeekly.com.
]]>
Introduction
AI is nowadays seen, heard, and used everywhere in day-to-day life right from helping in problem-solving to providing personalized recommendations based on our interests.
Recently you would have started seeing AI playing a major role in security surveillance too. In this fast-moving tech world, AI is likely to play a major role in the future in almost all the domains, however, the future is unpredictable, so let’s look into the following:
- What is AI ?
- What was the history of AI ?
- How it has evolved currently (Co-Pilot and Codex) and a look into the future of AI !
What is Artificial Intelligence?
Artificial intelligence (AI) is the simulation of human intelligence processes by computer systems.

Artificial intelligence (AI) is the simulation of human intelligence processes by computer systems.
Some applications of AI are:
- Natural Language Processing (NLP),
- Computer Vision (CV),
- Expert Systems,
- Speech Recognition, and
- Object Detection and Classification.
Before the boom of the AI era. Artificial Intelligence still existed as science fiction.
Artificial intelligence (AI) is a set of sciences, theories, and techniques including mathematical logic, statistics, probabilities, computational neurobiology, computer science that aims to imitate the cognitive abilities of a human being.
The Early Idea of machines with human-like intelligence dates back to 1872, in Samuel Butler’s novel Erewhon. The concept of AI has also been a crucial part of some sci-fi movies, for example, Director Ridley Scott gave AI an important role in most of his films like Prometheus, Blade Runner, and the Alien franchise, etc, the most relatable example is Terminator by James Cameron, in that SkyNet is a fictional artificial superintelligence system that plays as an antagonistic force. You might also hear the myth stories of the future controlled by Artificial Intelligence, Who knows? it could even be possible sooner than we think, with robots like Sophia!
The Future is here with Codex and Copilot
1. OpenAI Codex
- OpenAI codex is an Artificial Intelligence-based Natural Language Processing model developed by OpenAI. This helps in generating programming code given the comment about the required problem or a piece of code. GitHub Copilot is also powered by OpenAI. GitHub Copilot is one of the best use cases of OpenAI codex.
- Codex is a descendent of OpenAI’s GPT-3 model, a fine-tuned autoregressive model that can reproduce text more like a human. Upon GPT-3 – Codex is additionally trained with 159 GigaBytes of Python code from 54 million GitHub public repositories.
- To code with OpenAI codex users just need to give the command in English to this API. Codex is then just a complete piece of code for the given command. Currently, the codex is released as an open-sourced API but soon it may become as stated by the OpenAI in their document.
- You can register for codex by joining the waitlist.
2. GitHub Copilot
- Every programmer or developer loves to have a co-programmer to unite and work with, but the unfortunate situation is not all have a perfect pair. To solve this here comes GitHub Copilot. GitHub quoted this as “Your AI pair programmer”.
- GitHub Copilot is a VS Code extension that can autocomplete and synthesize code based on our inputs like comments and function headers. Copilot can work well with the programming languages Python, JavaScript, Go, Ruby and Typescript. More than just suggesting code, GitHub Copilot also analyses and draws content from the code on which the user is working and suggests a piece of code, it also helps in creating test cases for Codes.
- Copilot is also used to write prose, like it suggests upcoming lines based on our previous works. GitHub Copilot’s code sometimes works well but it doesn’t always give more perfect code as it is trained from public repositories mostly it’s not always the repositories that contain well-explained and well-structured code. When It is used in production it might lead to different bugs as it does not always follow the best practices.
- As GitHub Copilot can generate code as well as phrases, sometimes while creating a function it also generates some weird copyright comments like the ones present on the copyrighted codes. GitHub Copilot is a great resource for fast coding, it might have some mistakes but those are solvable by users.
- Copilot is in its first version, its limitations may be rectified in the future version.
- It’s a tool all programmers and developers can keep by their side. Try yourself
Latest Advancements
1. AlphaGo
In 2016, AlphaGo is the first computer program to beat the European Go champion (Fan Hui) and the world champion (Lee Sedol) then itself (AlphaGo Zero). AlphaGo was one of the complex games with 1080 possible outcomes, Go is known as the most challenging game for AI because of its complexity. This was one of the oldest games requiring multiple layers of strategic thinking.
2. OpenAI
OpenAI is an Artificial Intelligence research laboratory of parent company OpenAI Inc. This is also a competitor for DeepMind. The goal of OpenAI is to develop safe and user-friendly AI that benefits humanity.
- In 2015, OpenAI was formed by investors like Elon Musk, Sam Altman with Greg Brockman, Ilya Sutskever, Wojciech Zaremba, and John Schulman; They pledged over a billion USD to the venture.
- OpenAI stated that they are ready to freely collaborate with other researchers and research institutions making its research and patents open to the public.
- In 2016, Their beta version “OpenAI Gym” was released. OpenAI Gym is a platform for research on Reinforcement Learning. OpenAI Gym can only be used with Python language.
- In 2018, Elon musk resigned his board seat and remained as a donor.
- In 2019, OpenAI received a 1 billion USD investment from Microsoft.
- In 2020, OpenAI announced GPT-3, an NLP model trained on trillions of words of different languages.
3. Sophia

- Sophia, a humanoid AI robot developed by Hanson Robotics (Hong-Kong-based company). This is a social robot that uses AI to see people understand conversation and form relationships. This Robot was activated in February 2016 and Made its first public appearance in the mid of March 2016 at the Southwest Festival which happens in Texas, the United States.
- Sophia was the first-ever humanoid robot to get Saudi Arabia citizenship and also the first non-human to get a United Nations Title as it was named as the United Nations Development Programme’s first-ever Innovation Champion. Sophia imitates more human-like behavior compared to other humanoid robots. Sophia’s architecture includes intelligence software designed by Hanson Robotics, a chat system, and an AI system OpenCog designed for general reasoning. Sophia uses speech recognition technology from Alphabet Inc. and its speech synthesis was designed by Cerepoc. Sophia’s AI analyses the conversations and improves itself for future responses.
4. Google Duplex
- In 2018, Google I/0 showed Google Duplex, a voice Assistant using natural conversation technologies. Google Duplex is completely an automated system that can make calls or book appointments for you with a voice more like a human voice than Generated robotic voice.
- Duplex is designed in a way that it can understand more complex sentences and fast speech. Initially, this feature was launched only to Google Pixel devices.
- The core of Google Duplex is an RNN build using TensorFlow Extended. Model for Duplex was trained on a corpus of anonymized phone conversation data. It uses the features from the input data, history of conversation to optimize itself. This allows people to interact with an AI more naturally without a robotic voice.
5. Open-sourcing
- Google’s TensorFlow, a Python framework, was open-sourced in 2015 followed by Facebook’s PyTorch, a Python-based deep learning platform that supports dynamic computation graphs. The competition between TensorFlow and PyTorch gave more contributions to the AI and ML communities by giving more open-sourced updates.
- Many Custom libraries, packages, frameworks, and tools launched, this makes Machine learning to be easily accessible and understandable by all. On the other side, many researchers also open-sourced their work. This led all aspirants to learn it and apply AI in many different fields. The competition platforms like Kaggle are one of the key catalysts for increasing the growth of AI.
Back to the History of AI
In the early days of World War, Germany used a safe encrypted way of sending messages to other German forces. This was called the Enigma Code. Alan Turing, a British Scientist built a machine called the Bombe machine that can decode the Enigma code. This code-solving machine becomes the initial foundation for machine learning.
1. Alan Turing – 1950
In 1950, an English mathematician, computer scientist, and theoretical biologist Alan Turing published A paper – “Computing Machinery and Intelligence”. In this paper, he asked the question “Can machines think?” – This question was very popular during those days.

According to Alan, Rather than trying to determine if a machine is thinking, Turing suggests that we should ask if the machine can win a game, called the “Imitation Game”. This proposed “Imitation Game” was also known as the Turing Test.
2. First Artificial Neural Network – 1951

- In 1943, American Neurophysiologist Warren Sturgis McCulloch, in his paper “A Logical Calculus of the Ideas Immanent in Nervous Activity” stated the initial idea for neural networks. Warren Sturgis tried to demonstrate that a Turing machine can be implemented in a finite network of formal neurons.
- In 1951, Inspired by McCulloch’s paper, Marvin Minsky & his graduate student Dean Edmunds built the first Artificial Neural Network using 3000 vacuum tubes which stimulated 40 neurons. This first neural network machine was known as the SNARC (Stochastic Neural Analog Reinforcement Calculator) which imitated a rat finding its way around the maze. This was considered as one of the first towards building machine learning capabilities.
3. First Machine Learning Program – 1952

In 1952, Arthur Samuel wrote the first Machine learning program for checkers (Game AI), and also he was the first to use the phrase Machine Learning. The IBM computer worked on this algorithm and improved it. The more it played, studying the moves having winning strategies and incorporating those moves into its program. This algorithm uses a minimax strategy for selecting the next move. This ML program remembers all the moves played by it and combines them to find the winning set of moves with the help of a reward function.
4. AI name coined – 1956

The field of AI wasn’t formally founded until 1956, at a conference at Dartmouth College, in New Hampshire, where the term “Artificial Intelligence” was coined by John McCarthy, father of AI. He defines AI as the science and engineering of making intelligent machines. During those days it was also mentioned as computational intelligence, synthetic intelligence, or computational rationality which also make sense for AI. The term artificial intelligence is used to describe a property of machines or programs the intelligence that the system demonstrates.
5. IBM’s Deep blue – 1957

- In 1957, Herbert Simon, an economist, and sociologist prophesied that in a chess game the AI would beat a human in the next 10 years, before it happens AI then entered a first AI winter. After 30 years it was proven to be right. The operation of Deep Blue was based on a systematic brute force algorithm, where all possible moves were evaluated and weighted.
- In 1985, the development of Deep blue was initiated as a ChipTest project at Carnegie Mellon University.
- In 1987, this project was renamed Deep Blue thought Initially named Deep Thought.
- Deep Blue became the first computer to defeat chess grandmaster Garry Kasparov in the first match of a six-game match in 1996. However, Garry Kasporov wins the game 4 – 2. Again Gary Kasporov beat Deep blue for the second time, this time deep blue was heavily upgraded and called deeper blue. This computer defeated (3.5 – 2.5) the reigning world champion in the decider match. Later it was dismantled by IBM.
6. Perceptron – 1957
- In 1957, Perceptron was developed by Frank Rosenblatt at Cornell Aeronautical Laboratory.
- Perceptron was an early artificial neural network enabling pattern recognition based on a two-layer computer learning network. ANN is a machine model that has been inspired by the functioning of the brain.
- Rosenblatt perceptron is a binary single neuron model. Its input integration is implemented by adding weighted inputs to the existing weights. If the output is greater than the threshold. The neuron gives the output as 1 else it’s set to 0.
- Rosenblatt perceptron can solve some linear classification problems.
7. First AI lab

- In 1959, the first AI lab was established at MIT.
- In 2003, it was merged with the MIT Lab for computer science and called CSAIL.
- CSAIL is one of the most important labs in the world. The Lab lays the groundwork for image-guided surgery and NLP-based Web access, developed bacterial robots and behavior-based robots that are used for planetary exploration, military reconnaissance, and consumer devices.
- So far, 10 CSAIL researchers have won the Turing Award, which is also called the Nobel Prize of Computing.
8. ELIZA – 1965
- In 1965, ELIZA was an early Natural language program developed by Joseph Weizenbaum at MIT Artificial Intelligence Lab. This was the first program that was capable of attending the Turing test. This was also the first chatterbot created before the term chatterbot was coined. ELIZA uses pattern matching and substitution methodology to make it look like understanding the conversation. This was also the first time creating the illusion of human-machine interaction.
- ELIZA works by recognizing keywords or phrases and matches with the pre-programmed responses. Thus it creates the illusion of understanding the conversation and responding. However ELIZA is incapable of learning new words only with interaction, the words need to be fed in its script.

- In 1972, ELIZA and another Natural language program PARRY were brought together for computer-only conversation. In that conversation, ELIZA spoke as a doctor and PARRY stimulated as a patient with schizophrenia.
9. AI Winter
- AI Winter was a hard time for AI. AI encountered two major winters during 1974 to 1980 and 1987 to 1993. During this period much major funding was stopped, and the number of AI researches reduced drastically.
- “AI winter was the result of over-hype on this technology and impossible promises by developers and high expectations from clients and end-users, finally, the disappointment led to the emergence of AI winter.” – Still the case in 2021.
- Failure of machine translation led to the start of it. This was research by the US government to automate the translation of Russian documents. The major difficulty in this problem is word-sense disambiguation. This was less accurate, slower than manual translation, and also more expensive. So, the NRC National Research Council decided to cut the funding after spending a huge amount of 20 million dollars. Machine translation was put on a halt.
- Later in the 21st century, many companies have retaken it and received some useful results like Google Translate, Yahoo Babel Fish.
- During the AI winter, many criticized the end of AI, but the interest and Enthusiasm in AI gradually increased in the 1990s and showed a dramatic increase at the beginning of 2012.
10. MYCIN
- In 1975, MYCIN was an AI program developed at Stanford University, designed to assist physicians by recommending treatments for certain infectious diseases.
- The Divisions of Clinical Pharmacology and Infectious Disease collaborated with the members of the Department of Computer Science initiated the development of a computer-based system (termed MYCIN) that is capable of using both clinical data and judgmental decisions.
11. Convolution Neural Networks
- In 1989, Yann Leun (AT&T Bell Labs) applied a backpropagation algorithm to create Convolutional Neural Network (CNN), a multilayer neural network). Convolutional Neural Network is a neural network having one or more convolution layers depending upon its use case. CNN’s are mostly used in pattern recognition and image processing. CNN, also called ConvNets, was first introduced by Yann LeCun, a computer science researcher in the 1980s. Yann LeCun built on the work of Kunihiko Fukushima, a Japanese scientist, invented a basic image recognition neural network called recognition. LeCun’s version of CNN, called as LeNet ( Named after LeCun ), was able to recognize handwritten digits.
- In 1995, Scientist Richard Wallace developed ALICE
( Artificial Linguistic Internet Computer Entity ), a chatbot. Richard was inspired by ELIZA built by Weizenbaum. In addition to ELIZA, ALICE had natural language data collection. ALICE also won the Loebner Prize for three years ( 2000, 2001, and 2004 ). However, ALICE didn’t pass the Turing test.
- In 1998, the ALICE program was rewritten in Java language.
- In 2002, Amazon replaced Human editors with Basic AI systems. This paved the path for others on how AI could be utilized in business.
- In 2010, AI boomed because of the availability of access to massive amounts of data and heavy computing resources. CNN takes a new avatar and flourished in all subdomains of AI. Until the 2010s CNN remained dormant because Training CNN needed lots of computing resources and lots of data to train on.
- In 2012, Alex Krizhevsky designed AlexNet that uses multilayered neural networks with the ImageNet dataset used to create complex convolution neural networks that perform different computer vision tasks.
12. Eugene Goostman, a chatbot
- Eugene Goostman is a chatbot that portrays a 13-year-old Ukrainian boy, developed by programmers – Vladimir Veselov (Russian), Eugene Demchenko (Ukrainian), and Sergey Ulasen (Russian) at Saint Petersburg in 2001. This chatbot also passed the Turing test after a long run. This was portrayed as a 13-year-old as in Veselov’s opinion a thirteen-year-old is “not too old to know everything and not too young to know nothing”, a clever idea to ignore its grammatical mistakes.

- Eugene Goostman competed in several competitions, it also competed in the Loebner Prize and finished second in the years 2005 and 2008. On the hundredth birthday of Alan Turing Eugene Goostman, participated in the largest ever Turing test competition and convinced 29% of the judges that it is a human.

- In 2014, Eugene Goostman captured headlines for convincing 33% of the judges as if he was a real human during a Turing test. Event Organiser Kevin Warwick considered it passed the Turing test. This chatbot fulfills the prediction of Alan Turing as he predicted by 2000, machines would be capable of fooling 30% of human judges after five minutes of questioning. Soon it’s pass was questioned by critics that Eugene Goostman used personality quirks and humor to hide its non-human tendencies and lacks real intelligence.
13. AI Boom (Again) in 2010
AI boomed heavily after 2010. AI enters every field and makes a great impact on them. Andrew Ng, a computer scientist, quoted that, “AI is the new electricity”. The main factors for this boom are:
- Access to massive volumes of data. Thanks to the spread of the internet and IoT devices for generating Data.
- Discovery of Computer Graphics Card Processors (GPU’s) with high efficiency to accelerate the calculation of learning algorithms.
During the previous decade from 2010 – 2019, Many new AI-based companies emerge like
- Deepmind was initially founded in 2010 by Demis Hassabis, later acquired by Google for 400 million Euros in 2014.
- OpenAI, founded by Elon Musk, is a non-profitable organization doing lots of research in Deep Reinforcement Learning.
- And many new algorithms, AI frameworks like TensorFlow, imageNet, Facenet, NIEL (Never Ending Image Learner), Transformers, BERT (Bidirectional Encoder Representations from Transformers), etc., were developed, which optimizes the growth of AI.
14. DeepMind
DeepMind is an Artificial intelligence company a subsidiary of Alphabet Inc. DeepMind was started in 2010 by Demis Hassabis, Shane Legg, and Mustafa Suleyman. This start-up begins as Demis Hassabis tries to teach AI technology to play old games with the help of neural networks, as old games are a bit primitive and simple compared to that of this generation of games.
Key Points to note:
- DeepMind uses Reinforcement learning to make AI learn the game and master it.
- The goal of the founders is to create a general-purpose AI that can be useful and effective for almost all use cases.
- This start-up attracts major Venture Capitalist firms like Horizon Ventures and Founders Fund. Many investors like Elon Musk, Peter Thiel also invested in DeepMind.
- Later in 2014, Google Acquired DeepMind for 400 million Euros.
- In that same year, DeepMind also received the “Company of the Year” award from Cambridge Computer Laboratory.
- In 2017, DeepMind created a research team to investigate AI ethics.
15. Siri
In 2011, Apple introduced Siri, It was the world’s first substantial voice-based conversational interface. The introduction of Siri led to the use of AI in virtual personal assistants. Many companies started creating their model of Virtual personal assistants as ALEXA for Amazon in 2014, Cortana for Microsoft, Google Assistants for Android.
16. Watson, “Jeopardy” winner
In 2011, the computer giant’s question-answering system Watson won the quiz show “Jeopardy!” by beating reigning champions, Ken Jennings and Brad Rutter. Watson was a room-sized machine made by IBM named after Thomas J Watson. IBM also made Watson a commercial product after its success.
17. Google X

In 2012, Google X (Google’s search lab) will be able to have an AI recognize cats on a video. Google’s Jeff Dean & Andrew Ng trained a neural network that has More than 16,000 processors to detect cats and dogs using this algorithm. Later when Alphabet Inc. was created Google X was renamed as X. This lab is working on many interesting and futuristic projects.
Some of the exciting works at this lab are:
- Google Glass – A research and development program to develop an augmented reality head-mounted display (HMD).
- Waymo – Driverless car. After the success of this project, it emerged as a new company under Alphabet Inc.
- Google Brain – A deep learning research project. This project was considered one of the biggest successes under Google.
- Google’s driverless – In 2014, Google’s driverless car passed Nevada’s self-driving test.
Conclusion
Now, AI is touching new heights every day with new applications in different domains. The expectations of AI are also increasing day by day. The Technology once seemed it was over, has boomed again. For this advancement of AI major credits goes to the scientists who worked on it earlier. For every futuristic solution, we need to look up the past. Artificial intelligence acts as the main driver of emerging technologies like robotics, big data, and Internet of Things and it will continue to act as a technological innovator for the foreseeable future. I have taken you through a historic journey of AI. Hope you enjoyed it and got some new insights through this blog.
If you liked this Blog, leave your thoughts and feedback in the comments section, See you again in the next interesting read!
Happy Learning!
Until Next Time, Take care!
– By Kabilan
Checkout this Blog on “8 Most Popular Types of Activation Functions in Neural Networks” here !
The post A Comprehensive History of AI is here: First AI Model to Latest Trends first appeared on TheHackWeekly.com.
]]>The post 8 Most Popular Types of Activation Functions in Neural Networks first appeared on TheHackWeekly.com.
]]>
1. Introduction
Deep Learning is probably one of those things that everyone thinks is magical and usually, I take immense pleasure in seeing the reaction they have when I tell them it’s essentially matrices that are unlike the nodes they expect but Neural Networks aren’t limited to that and neither, is that the thing, that makes it special.
For all the beautiful minds out there, the modified quote below is from The Lord of the Rings but sad that it couldn’t be true.
“One Activation to Rule them all
One Activation to find them
One Activation to bring them all
And in Layer bind them”
Behind the scenes, neural networks learn by a process known as backpropagation which is essentially propagating the loss backward in the neural network or as a few like to say chain rule coming to life. On the other hand, the output in neural networks is generated by the process known as feed-forward which is basically nothing but a set of linear operations.
The mathematics behind it is intriguing but these statements lead to one interesting question:
- If feed-forward is linear then why are neural networks so hyped?
Well, my friend, I’ll ask you to hold your horses and fasten your seatbelt because it’s gonna be one hell of a ride!
P.S. I expect you are familiar with Feed Forward and Backpropagation. If not – no issue, we’ll be getting a bit into their working before completely understanding Activation Functions.
2. What are Activation Functions?
Activation Function, also known as Transfer Function is nothing but a simple mathematical function and like any function, it takes an input and gives some output corresponding to it.
In neural networks, the activation function of a node defines the output of that node given an input or set of inputs. An integrated circuit could be considered as a digital network of activation functions that can be “ON” or “OFF”, based on the input.
Yes, I’m indeed saying that it could be any function – sigmoid, tanh, Softmax, ReLU, Leaky ReLU, etc. but the below questions may arise?
- Does using a particular activation function have any effect on performance?
- Why use activation functions anyways?
- What are the popular ones?
Let’s see all of them one by one.
3. Why use Activation Functions?
Before diving into the answer let’s take a walk down the memory lane and understand the feed-forward process again. Take a look at the picture below.

Although that pretty much sums it up. Let’s go through it briefly. In the image on top, there is a single node of the layer with w1 and w2 being the weights associated with the inputs x1 and x2. This node does nothing but multiplies the weights to the corresponding inputs and summing them up.
For example, x1 has weight w1 and x2 has weight w2 associated with them so they multiplied and summed the result in x1*w1+x2*w2.
Now let’s talk about the network at the bottom which is a simple neural network. In the hidden layer, we have 2 nodes, let’s name the top node as node A and the bottom node of the hidden layer as node B.
The output from node A is the result of summing the products of x1 and x2 with their weights associated to node A i.e. w1 and w3 respectively, let’s refer to the output of node A as o1. Similarly, the output from node B is the result of summing the products of x1 and x2 with their weights associated to node B i.e. w4 and w2 respectively, let’s refer to the output of node B as o2.
Now that we have the outputs of both nodes in the hidden layer, we can now calculate the output of the neural network by summing the products of o1 and o2 with their weights associated with the output node i.e. w5 and w6 respectively. But we know that this operation is basically a matrix multiplication and we have the matrix W or weight matrix and O the hidden layer output matrix so the output becomes W x O. If we add the bias term it becomes W x O + B.

The Problem is, this output is linear in nature so it’s not able to capture the complex patterns in the dataset. If somehow we can add non-linearity in the result we might be able to do that and that’s exactly what activation functions do. We apply activation functions on the outputs of the hidden layers to introduce inequality so that our model is able to capture complex patterns in the data.
Well, that was elaborate but hopefully, this is clear now. Let’s go ahead and explore more about the 3 activation functions, the Problems associated with them, and How other activation functions overcome them?
4. Three Activation Functions
4.1 Sigmoid Function
4.2 Hyperbolic Tangent Function
4.3 ReLU – Rectified Linear Unit
4.1 Sigmoid Function
If you are familiar with Logistic Regression then chances are, you already know about sigmoid or logistic function one but just for formality let’s revisit it again:

The function above is the sigmoid function. It basically takes an input and maps it to a value between 0 to 1. Now, this sigmoid function can be used as an activation function for our hidden layer and it’ll work fine, kinda. I mean it does introduce non-linearity leading to complex decision boundaries but as the number of hidden layers increases, we’ll run into the problem of Vanishing Gradients. Just for a refresher, Decision Boundary is a line that separates the points into the different regions and each region corresponds to a different class.
In the Vanishing Gradient problem, the gradients become extremely small leading to almost no change in weights and no change in weights means no learning. Before understanding why it happens let’s take a look at the derivative of the sigmoid function.
![]()
Interesting isn’t it? The more interesting thing is that the maximum value attained by the derivative of the sigmoid function is 0.25, I know you’ll be all like “what’s so interesting in that?”.
To that, I’ll say that the product of 2 numbers, both less than 1, results in a lesser value and where does that multiplication happen?
Chain rule! And like I said before, backpropagation is nothing but chain rule coming to life. So as the network back propagates the error deeper, the values of gradients keep getting smaller since the no. of gradients being multiplied increases. To all those who forgot chain rule and backpropagation, the following image should help.
 That’s the reason that in deep networks with sigmoid activation the end layers keep learning but the learning becomes less until it doesn’t happen as you go deeper.
That’s the reason that in deep networks with sigmoid activation the end layers keep learning but the learning becomes less until it doesn’t happen as you go deeper.

For shallow networks and not-so-deep neural networks, it’s kind of ok to use sigmoid but as you go to neural nets with 10 or 20 or 50 layers things get really serious.
So, what is the solution for this? Well, the simple solution is to use an activation function that does not squish the inputs and ReLU does exactly that. But before that let’s take a look at another function loved, or used, by LSTMs i.e. tanh function.
4.2 Hyperbolic Tangent Function
If you have studied Trigonometry then chances are you’ve already heard about it. I apologize in advance because I’ll have to take you through that trauma again. Equation wise tanh function looks like this:-

Hyperbolic Tangent function, or tanh function, is a rescaled version of sigmoid function and like the sigmoid function, it squishes the input between a range, but this range is a bit bigger than sigmoid i.e. [-1, 1]. Not just that in comparison it is also much steeper near zero than sigmoid. But these things make much more sense when you look at the following equation:-
![]()
This equation justifies the point that tanh is basically stretched and readjusted sigmoid function which probably is the reason why property-wise tanh is quite similar to the sigmoid function. In fact, just like the sigmoid function, its derivative can be represented by its original value as well.

These things aside, tanh actually performs better than the sigmoid function when used as an activation function. But why? For that let’s take a look at a research paper by LeCun named “Efficient BackProp” written in 1998 the time when deep learning was usually limited to paper. Here is an excerpt from it:-
Sigmoids that are symmetric about the origin are preferred for the same reason that inputs should be normalized, namely, because they are more likely to produce outputs (which are inputs to the next layer) that are on average close to zero.
This is in contrast, say, to the logistic function whose outputs are always positive and so must have a mean that is positive.
Let’s dissect it piece by piece. The first point says that symmetric sigmoids, i.e. tanh in this case, are preferred because they produce outputs nearing zero. That’s true in logistic function output range was from [0,1] making the output positives but the tanh function has a range [-1, 1] hence the mean value of layer comes very close to 0. When weights are centered around 0 the value of gradients is larger and yes that’s like sigmoid except in this case the gradients are much stronger and hence convergence is faster.

But sadly it suffers from the problem of vanishing gradient too. So we still need a fix for that. There is another problem of the error surface being flat near zero but as LeCun said adding a Linear term can fix that. By that, he meant using tanh(x) + ax and as a bonus fact let me tell you this, LeCun actually told the preferred sigmoid to use as:-

4.3 ReLU – Rectified Linear Unit
Of all the activation functions I have known, this was the most simple…
– Spock
We talked about what a vanishing gradient is and how it can hinder the learning process of initial layers, so a good question to ask would be is there any activation function that won’t let the vanishing gradient problem happen? Well, that’s exactly what ReLU helps us with. If squishing the output is making the gradients disappear then let’s not! Relu is a simple guy, he sees negative and he makes it zero  . To understand it better let’s see its equation.
. To understand it better let’s see its equation.
![]()
So how does ReLU solve the vanishing gradient problem? Well, the derivative of ReLU can only be either 0 or 1 so you don’t need to worry about the gradients decreasing as it gets deeper. Even functions with pointy edges or breaks, like ReLU at x = 0, are considered non-differential at that point but for ReLU we can simply define the gradient at x = 0 as 0 or 1 won’t matter.
I mean this is as simple as it can get and that’s basically the principle behind ReLU is the output is negative make it 0 else keep it as is. Wait wait wait! What? If ReLU just lets the input be in case it is positive and only makes it 0 when negative then it’s it basically a linear function with a restriction? Well, you are not wrong in that statement, in fact if you look at the graph it is the same as a linear function for the +ve x-axis.
Why does ReLU work?
If ReLU is basically a linear function for the +ve x-axis then how does it introduce non-linearity to the net? Well, to keep it simple the ReLU function is nonlinear overall so it does introduce non-linearity. But you won’t be satisfied with that sort of explanation right? So let’s do a bit of math to understand, a function is said to be non-linear if it does not follow the following property:-
![]()
For ReLU the above statement is false in the case where either a or b is negative. So that does prove that ReLU is not linear and hence can introduce non-linearity to the net. But if that doesn’t seem convincing to you take a look at the following picture:-

So let’s understand the above picture but before that let’s establish some basic understanding of graph manipulation. When you add some value to a graph you shift the graph on the x-axis so for identity function i.e. f(x) = x if we add a value of 5 making it f(x) = x + 5 the graph will shift by 5 units in the direction of -ve x-axis.
That means adding a value to the function makes it shift in -ve x-axis direction and subtracting a value to the function makes it shift in +ve x-axis direction. Similarly, multiplying a +ve value to the function makes it stretch in +ve y-axis direction, and multiplying a -ve value to the function makes it stretch in -ve y-axis direction.
Now that we have some basic idea about graph manipulation we can go ahead and ask ourselves, Where have we seen these multiplying and adding? The answer is Feed-Forward! Yep, we multiply the input value with weights and add bias, if any, to the result.
Doing this to a ReLU function can make stretch and shift and since the same thing happens to other nodes too we’ll have a bunch of transformed ReLU functions which will be added together and passed to the next layer, and as seen in the picture when you add a bunch of transformed ReLU you get a non-linear function and that’s why even though ReLU may seem linear but when transformed and added together creates a non-linear function.

So ReLU is perfect?
ReLU is widely used in neural networks and even now you’ll see it being used a lot, like a lot. So that’s good, right? We finally have our perfect activation function. YAY! Well, NO. Sorry about that really but even though it might work in most cases but in some cases, it won’t, due to something known as the Dying ReLU Problem.

5. Dying ReLU Problem
It was going so well that we felt like we finally met the chosen one but all the good things eventually came to an end and in the case of ReLU the reason was Dying ReLU Problem, which is a really cool name but what makes ReLU have this problem? Or even a more basic question, what is the Dying ReLU problem? Do we have a fix? Let’s discuss that.
So as discussed earlier we know that ReLU is zero for all the negative input. That actually is something that worked for us adding non-linearity to output and for the most part, it’ll work fine but in some cases what happens is that many nodes start giving negative output either due to a large weight or bias term, which leads to the nodes outputting 0 when ReLU is applied. Now if this happens to a lot of nodes then the gradient also becomes zero and if there is no gradient there is no learning.
This doesn’t happen every time though so ReLU is not useless. So why does this happen? Well a couple of reasons:-
- High Learning Rate: High Learning Rate can lead to the weights becoming negative which may make the output term negative. Setting the learning rate to a lower value might fix the problem.
- Large Negative Bias Term: If the bias term is largely negative then it could lead to the final output becoming negative.
So we know what the Dying ReLU problem is, we know what causes it and we know one way to fix it. Well, actually there is another way to fix it i.e. New Activation Function. Yay?

6. Modifying ReLU
The main cause of the dying ReLU problem is due to negative output becoming zero, in order to cure this what we can do is not make the negative output zero. Cool! So what should we replace it with? Well, plenty of things as it seems and that’s where variations of ReLU come and the most popular one being Leaky-ReLU. So what are these variants and what’s the difference? Let’s take a look at 5 Variants:
- Shifted ReLU
- Leaky ReLU
- P-ReLU
- ELU
- GELU
6.1 Shifted ReLU
Shifted ReLU is an adjusted ReLU which instead of making negative values as zero you change it with another value. In fact, equation wise it is pretty similar to ReLU. Since the negative value doesn’t become zero the nodes don’t get switched off and the Dying ReLU Problem doesn’t occur.
![]()

6.2 Leaky ReLU
Leaky ReLU is another ReLU variate that aims to replace the negative part of ReLU with a line of a small slope, commonly 0.01 or 0.001, now since negative values don’t become 0 the nodes don’t get switched off and the dying ReLU problem doesn’t occur.
![]()

6.3 P-ReLU
P-ReLU or Parametric ReLU is a variation of Leaky ReLU variate that aims to replace the negative part of ReLU with a line of a slope α and since negative values don’t become 0 the nodes don’t get switched off and the dying ReLU problem doesn’t occur.


6.4 Exponential Linear Unit – ELU
ELU is another activation function and it is known for being able to converge faster and produce better results. It replaces the negative part with a modified exponential function. There is an issue of added computational cost but at least we don’t have a dying ReLU problem.


That’s pretty much all the ReLU variates you should be familiar with and each of them has its set of advantages and disadvantages but one thing they have in common is their ability to prevent dying ReLU problems.
6.5 GELU – Gaussian Error Linear Unit
I know and yes dying ReLU is fixed but this activation function is something I wanted to talk about because of it being used in SOTA models. GELU or Gaussian Error Linear Unit is an activation function that has become a popular choice in Transformer models. Its most recent use case is in the CMT model, a paper published in July 2021. GELU function is a modification on ReLU, well sort of. For positive values, the output will be the same, except from 0 <= x <= 1, where it becomes a slightly smaller value.


7. Why Activation on CNN?
In CNN-based networks, you must have often seen ReLU being used over feature maps generated by CNN Blocks but why do we use that? I mean in normal neural nets it is to introduce non-linearity but what about CNN? Well, let’s find out.
CNN aims to find various features in an image and even though the process may seem complex the operations in CNN are linear in nature. Thus the reason activation is used in CNN is the same as that of a normal layer i.e. to introduce non-linearity to make CNN capture better features that can generalize to a particular class.
8. Activation over Output Layer – Is it necessary?
We’ve learned about the reason we use activation functions over hidden layers but their use is not just limited to hidden layers. We can use the activation function over output layers too. But what is the point? Let’s take a look at the common problems:-
- Regression Problem: You don’t need an activation here since the problem requires you to get continuous output that may or may not be in a range.
- Binary Classification Problem: You need to pass the output values to a sigmoid activation to convert them into a probability to be used to classify it as 0 or 1 depending on the threshold.
- Multi-Class Classification Problem: You can pass the output values to a softmax activation to interpret as probability but as far as computation of class is concerned you can skip it.
9. Custom Activation Function Layer in PyTorch
Activation functions are just normal mathematical functions so you can create a python function to define the equation and use it in the feedforward. However, you can also create an activation layer in PyTorch using nn.Module. If you are familiar with PyTorch then this will feel very much like defining a feed-forward, probably because it is. Let’s go ahead and create our own activation class for Parametric ReLU.
There you go that basically defines the return value of the activation function in the forward function and you are ready to use this as a layer. Let’s go ahead and plot this to see if it’s actually correct.

10. Conclusion
Wow, that was a lot of information to process but I hope it was fun and interesting for you to read. Activation Function is a concept that almost everyone knows but the impact it creates is something very few like to ponder over. The reason they are used, the effect each has on the results, etc. such questions may seem simple but the dynamics behind them could be much more complex, hence it becomes important to understand them and I hope you were able to understand it.
If you liked this Blog, leave your thoughts and feedback in the comments section, See you again in the next interesting read!
Happy Learning!
Until Next Time, Take care!
– By Herumb.
Checkout this Blog on “A Comprehensive History of AI is here: First AI Model to Latest Trend” here !
The post 8 Most Popular Types of Activation Functions in Neural Networks first appeared on TheHackWeekly.com.
]]>