

Deprecated: Creation of dynamic property Jetpack_Carousel::$localize_strings is deprecated in /home3/thehackw/public_html/wp-content/plugins/jetpack/modules/carousel/jetpack-carousel.php on line 523

1. Logistic Regression – Introduction
We are going to start with what logistic regression is?
- Logistic Regression, is used in statistics to estimate (guess) the probability of an event occurring provided we have some previous data, which means to predict a data value based on prior observations of a data set.
- Logistic Regression works with binary data, where either the event happens (1) or the event does not happen (0).
- It is named ‘Logistic Regression’ because its underlying technique is quite the same as Linear Regression. It is a simple machine learning algorithm that is most commonly used for classification problems in the Industry.
Note: The main aim of the blog is to get you to code and use it in predictions while knowing the theory behind it, so you don’t miss out on both theory and practical coding.
From here, the first question that comes to our mind is, what’s wrong with linear regression for a classification problem, Right?
Well, there are a couple of problems and let’s discuss them briefly:
1.1 A slightly far off input disturbs the entire algorithm
I will explain this with a hypothetical scenario. Imagine a problem where we are to predict whether a tumour is benign or malignant. In that case if we plot a best fit line using linear regression then it will look somewhat like this.

Clearly from here, you can say that the best fit line is not a good threshold to predict whether a tumour is benign or malignant. This is a simple way to understand why linear regression is not suitable for classification tasks as the inputs are in zero and one.
1.2 The predicted value of y is much larger than 1 or much lower than 0
Now we have established why linear regression fails for classification problems, so let’s get straight into logistic regression. Before we do anything, we have to first understand how to interpret the output from the logistic regression model.
This logistic regression model will predict a output between the range of 0 and 1, 0 < y_pred< 1.
Here, y_pred is the estimated probability of getting y = 1 if the input is x.
For example:
Suppose the value of y_pred is 0.9, then its interpretation is that the probability of y being 1 is 90%.
Mathematically, hθ (x)= P(y=1| x ;θ), hθ (x) = y_pred
Symbols used: _ (underscore) means subscript and ^ (power cap) means superscript
2. Computing the Predicted Output
Now with all that being said, let’s compute the predicted output. We will start this quest by taking a look at the logistic regression equation.

Here x1 and x2 are the input features. For example, let’s say we are predicting whether a tumour is malignant or benign, then x1 will be the area of the tumour and x2 will be the perimeter of the tumour. There will be many more input features as well but first we will continue with these two features.
Next comes w1 and w2.
These are the weights associated with the logistic regression model. The input value is fixed for a particular datapoint, so the only way to change the value of the output is by tweaking the weights and the biases ( bias is the term b here, but we will discuss that later ) only.
For example,
If our model is predicting the output probability to be 0.10, which is suggesting that the probability of the tumour being benign is high, but in reality it is malignant, then we can change the value of the weights and biases to make the output probability to be above 0.5.
Now what should be the initial value of the weights ? We can initialise the weights to be of any value from negative infinity to positive infinity in theory, but for practicality we have to keep in mind a few things. What are these few things ? We will discuss that a little later. But for now keep in mind that we should not initialize the weights very high or very low. It can be around the range of [-0.5,0.5] or [-1,1] or (0,1].
Now we will discuss the bias or the term b in the equation. Bias is added to the equation so that the decision boundary does not pass through the origin every time. It is much like the y-intercept in the equation of a straight line. If the y-intercept is not present or is zero then the line always passes through the straight line. It is generally initialized with the value of zero but its value changes to some random number that gives the best output after gradient descent ( we will discuss gradient descent in depth in this article as well ).
Now we jump into the next step of computing the predicted output. As you can imagine, all these values like x1 , w1 , etc have random values and therefore the value of z will not be in the range of [0,1] or [-1,1] ( considering -1 to be the opposite case ). So we pass this value of z to a function known as activation function which decreases or increases the value of z to the range of [0,1] or [-1,1] and that we can accept as our predicted output. I will discuss some activation functions and that will make things clearer.

2.1 Sigmoid Activation Function
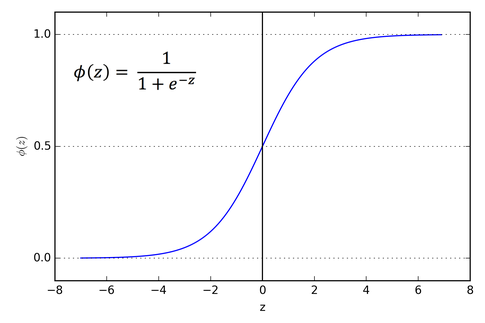
The sigmoid activation function looks somewhat like this : φ(z) = 1/(1+e^(-z))
If you compute the range of the function you will find it to be (0,1). And for z = 0 the function returns 0.5. The behaviour of the function will be more clear from this Graph.

Image courtesy
{kind=link}
The graph shows that if the value of z is very low then the output is generally zero and if it is very high then the output is generally one. From here we can also get a idea that if the value of the weights are very low then the value of z will be very low and therefore the output will always be very close to 0 and when the value of the weights are very high then the value of z is very high and the output will always be one. This is one of the reasons why the value of the weights should not be in extremes.
2.2 Tanh Activation function
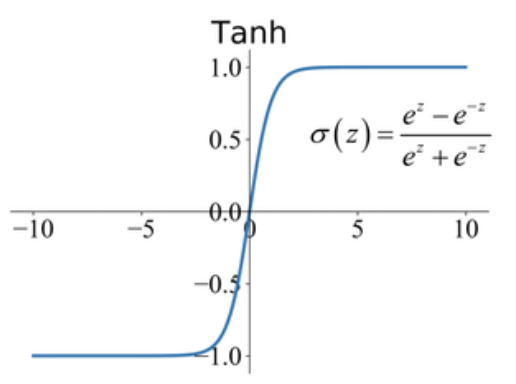
The Tanh activation function equation looks something like this :

Image courtesy
{kind=link}
It is very evident from the graph that the range of the tanh function is between [-1,1] and has a value of 0 at z = 0. Also the nature of sigmoid and tanh curve are quite similar. Now a question arises if we have Sigmoid then what is the need of tanh ? In case of tanh the data is centred around zero and the negative inputs will be mapped strongly negative and the positive input will be mapped strongly positive.
5 most used Activation functions are
- Sigmoid activation Function: Equation – φ(z) = 1/(1+e^(-z))
- Tan h activation Function: Equation – σ(z) = ((e^z – e^(-z))/(e^z+ e^(-z))
- ReLu activation Function: Equation – y = max(0,x)
- Leaky Relu activation Function: Equation – y = max(0.01*x,x)
- Softmax activation function: Equation – softmax(x_i) = e^x/∑_j e_j
Finally we have summarized the entire process through this image. Take a look at this for getting the complete picture.

3. Understanding Loss and Cost Function
We have our predicted output in our hand right now and also the original output from the data. But we realise that our model has not done a very good job and has got most of the predictions wrong. After thinking a little we realise that this is quite certain as the weights and biases had absolutely no correlation to the original output. So we now want to convey to the model that it has performed very poorly and for that we need something to quantify the mistake of the model. This is where the loss function comes into the picture. There are many loss functions out there but the two that are mostly used are Mean Squared Error loss function, about which you would probably know if you have studied Linear Regression and the second one is Cross Entropy Loss function which is used in case of Logistic Regression and we will discuss that here.
I will start explaining cross entropy loss function directly from the equation:

Here, y = original output and y^ = predicted output.
We know that original output or y can have only two values either one or zero, for example the tumour can be either benign or malignant.
If we plug y = 0 in the above equation it reduces to : Loss = -log( 1-y ̂) whose graph looks somewhat like this:

Therefore, if the model predicts 1 while the true label is 0, then according to the loss function the error is infinity and as the prediction approaches 0 from 1, the error gradually decreases and finally, if the model predicts 0 then the error is zero as the true label is zero.
And if we plug y = 1, then the equation reduces to -log(y ̂), whose graph looks somewhat like this:

Here, if we analyze this graph we will find out that when the predicted value of y is 0 and the true label of y is 1, then the error is again infinity as the prediction is completely wrong and as the prediction approaches 1 from 0, the error will gradually decrease and will finally become 0 if the predicted value is 1 which is also the true label. Mind you, the predicted output is basically a probability and will be any value between 0 and 1, not exactly 0 or 1.
With this we have got an idea of how the loss function actually works, how it is able to actually tell the model about its performance but all this discussion above was about one data point and now we will have to extend this entire thing for all the data points and compute the overall loss so we can get a better picture of how the model is. For this we introduce something known as the cost function. In the cost function, we take the sum of all the losses from all the data points and then divide it by the total number of data points. I will introduce the equation of the cost function and it will make it clearer.

In other words we take the average of all the losses that we computed from all the data points. I hope this entire thing made some sense. If not, then I will suggest you to read this again or take a look at some other articles and lectures for clarity. Here we end our discussion about the cost and loss function and we will move onto the next step.
Some of my suggested lectures and blogs are:
- Youtube Video on logistic regression – Here.
- Youtube Video on cost function – Here.
- Coursera course – Here.
4. Optimising Weights Using Gradient Descent
After we are done computing the loss and the cost function, we now have to reduce the value of the cost function ( Not if we have a very less cost in the first attempt itself, but that is almost impossible). So now is the time to change the weights properly so that the
predicted output is close to the original or true output and therefore the value of cost function is reduced or can be minimised as much as possible. For this we will be using the gradient descent algorithm. The aim of gradient descent is to optimise the value of all the weights which in this case is w1 and w2 and the biases as well.
The gradient descent algorithm looks somewhat like this:

Here, w1 = one of the weights in the model
:= is update equals
α = learning rate
j = cost function
Until now, we knew that cost function is a function of y and y_pred, but I have written it to be a function of y and w1. This is because y_(pred )is a function of w1,w2 and b but we will consider w2 and b constant for this case and we will do partial differentiation with respect to w1. That is why I have written it to be a function of w1.
If we plot the graph of cost function with w1 or weights of the model, we will find out that it is a parabolic curve just like the one shown below. I am skipping the mathematics of it in this article. Now, we know that taking a derivative is basically drawing a tangent at a point in the curve where the derivative is taken. With all that being said, let’s start breaking down the gradient descent equation. w1 is the initial weight that is the one we initialised. Let’s assume that w is the point for which the graph will have its minima and w1 is a point on the curve which is not equal to _w, therefore j(y,w1)> j(y,▁w). Refer to the graph below if you are having problems with visualizing.

Image courtesy
Now, if we take derivative ( we are taking the derivative as in the equation of gradient descent we need the derivative of cost function ) at w1, the value of the derivative will be positive. Why ? This is because tanθ,where θ is the angle made by the tangent with the x-axis therefore is acute and so tan θ will be positive. α,Here is the learning rate which is positive and is generally less than 1. I will discuss its significance a little later.
Now, the equation looks something like this: w1 := w1 – (positive number)*(positive number) ,
that is the value of w1 will slightly decrease and will be updated. Now this entire process will continue until the minima is reached where the value of the derivative will be zero and so w1 will not change anymore. If the value of α is high then the value of w1 might get lower than w_ was we are subtracting a big number from w1. So, if we keep the value of α high then it might overshoot the minima and the minimum point may never reach instead we get to a point where the cost increases than before.
Now if we keep the value of α very small then the number getting subtracted from w1 will be very small and we will take a very small step towards the minima. The steps will get even smaller as we reach closer to the minimum as the value of the gradient there is also very small. Therefore it will become a very very long process. To tackle this kind of problems with the Gradient descent we have made some modifications to the gradient descent algorithms, which I will not discuss in this article but feel free to research about them. In reality we generally fix a number of iterations like 500 or 2000 for gradient descent after which we stop it.
This entire process is repeated for all the weights and biases until we get the minima for all of them.
I hope I was able to show you the beauty behind logistic regression. It might be a little difficult to grasp the entire thing in one read if you have never studied any of these things before. But hopefully, if you persist and read it a few more times, it will get clearer.
5. Coding Logistic Regression from Scratch
We have understood the Theory of logistic regression, but now we want to use it in practice.
First, let’s build a logistic regression model completely from scratch to make predictions on fake data and then we will use the scikit- learn library to build a logistic regression model and make predictions on the same data and will finally compare the accuracy as well.
In the code below, you can also visualize how the values from the cost function changed as weights and biases were changed. I have also included a decision boundary to give you an intuition about how the predictions are done
However, I have not done any feature engineering or data visualization or parameter optimization. In case you are interested in improving the accuracy than what we have got, try doing some optimisations and feature engineering.
6. Theory of Neural Networks
6.1 Computing output of a single layer Neural Network
Now we have understood the working of a logistic regression model and we will use that knowledge to get through to a simple neural network. A neural network is nothing but many logistic regression units connected to each other in different layers. Like in this case, the hidden layer has 3 Logistic Regression units and they are attached to each other. Now we will dive in to see how to compute the output of this neuron below.

Image by Author
Each Lr unit is represented like this :- a_y^([x]), here x is a number that represents the i^thhidden layer which in this case is 1 as there’s only one hidden layer and y is the i^th neuron in that hidden layer, like for the first one ( from the top to bottom ) the value of y will be 1 for the second one will be 2 and for the third one will be 3.
The first one will be represented as a_1^1, second one as a_1^2and the third one as a_1^3.
The function of these neurons in the hidden layer is to pass a value to the neuron at the output layer. Then in the output layer also, a logistic regression unit is used to compute the output.
The y_(pred) is calculated like this:
the weights in this case are not similar to the weights that we used initially during the calculation of the neuron units in the hidden layers. I hope this gives a good intuition of how a prediction is computed in an artificial neural network. The example that we have taken here is one of a shallow neural network but as we increase the number of hidden layers, a deep neural network is formed.
6.2 Backpropagating for optimizing weights
Once we are done computing the predicted values, again it is time to calculate the cost function for the neural network to see how accurate our neural network is. A cost is calculated for all the logistic regression unit in the neural network and then the derivative of the function j(θ) is taken with respect to w_i to find the best value of w_i.
The entire mathematical calculation for the back propagation of neural nets is a little bit complicated and therefore we are not discussing it here but we will try to cover it in upcoming blogs.
And with this we end the theory of neural networks. I hope this has given some clarity about the behind the work of neural networks.
To code a neural network we will need a library like tensorflow or pytorch. Although it is absolutely possible to code it from scratch using numpy and pandas but that is too complicated and we will have to compute the derivative of many functions, that is why we will be needing pytorch or tensorflow. How I wish to make a blog that discusses the matrix way of looking at neural networks and then cover the code part of it.
7. Conclusion
I hope the blog has given you a good idea about logistic regression and how it works.
The blog has taken you from understanding the processes and calculations behind the logistic regression algorithm and giving a brief demo how to use it practically to the basic working of neural networks. What goes behind a neural network and what are calculations involved in it.
If you liked this Blog, leave your thoughts and feedback in the comments section, See you again in the next interesting read!
Happy Learning!
Until Next Time, Take care!
– By Sayantan
Impressive, Interesting, Useful blog… Thanks for the blog..
Great blog really
Very well written. Looking forward to many more great write ups! Keep it up.
Thank you so much !!
Logistic regression explained nicely, very good detailed blog
Thank you !!
Well written and really informative blog!
Thank you, keep supporting.
Nice and quick read
Thanks !!
Amazing write-up! 👌
Thank you, keep supporting 😁
Well written ✨
Thanks !!
Wow great stuff
Thank you !!
It was amazing blog 😍
Thank you so much !!
One of the best beginner blogs.
Really liked it.
Thank you !!
Very Insightful blog
Thank you Sayantan
Thank you so much !
Nice read
Thanks !! 😁
Really Comprehensive
Thank you .
Well written, as always!
Thank you so much !!